
Community virus surveillance
Even highly effective vaccines will not save us from the need to monitor severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) activity, perhaps for years to come. Public health institutions will need early warning of any uptick in cases to prepare and deploy interventions as required. Riley et al. developed a community-wide program that was designed to detect resurgence at low prevalence and has been used to track SARS-CoV-2 virus across England. In the four rounds of sampling from May to September 2020, almost 600,000 people representative of all communities were monitored. The results revealed the greatest prevalence among 18- to 24-year-olds, with increasing incidence among older age groups and elevated odds of infection among some communities. This testing approach offers a model for the type of real-time, country-wide population-based surveillance work that needs to be conducted to monitor SARS-CoV-2.
Science, abf0874, this issue p. 990
Abstract
Surveillance of the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) pandemic has mainly relied on case reporting, which is biased by health service performance, test availability, and test-seeking behaviors. We report a community-wide national representative surveillance program in England based on self-administered swab results from ~594,000 individuals tested for SARS-CoV-2, regardless of symptoms, between May and the beginning of September 2020. The epidemic declined between May and July 2020 but then increased gradually from mid-August, accelerating into early September 2020 at the start of the second wave. When compared with cases detected through routine surveillance, we report here a longer period of decline and a younger age distribution. Representative community sampling for SARS-CoV-2 can substantially improve situational awareness and feed into the public health response even at low prevalence.
Ahead of widespread rollout of effective vaccines in most countries (1–3), severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection continues to cause substantial COVID-19 morbidity and mortality globally (4). As variants with potentially increased transmissibility emerge (5), populations around the world continue to trade off between social interactions and risk of infection (6). However, reduced social contact (7) has adverse effects on levels of economic activity (8), non-COVID-19–related health, and overall well-being (9). The ability of both individuals and governments to continue to balance these competing demands requires accurate and timely knowledge of the spread of the virus in the population so that informed choices about interventions can be made.
Data streams based on respiratory symptoms, such as those used for COVID-19 surveillance in most countries, are prone to biases that can obscure underlying trends, such as variations in test availability and test-seeking behavior (10). Some countries have augmented these systems with surveys of virus prevalence in the wider population, but these have mostly been one-off activities, for example, as in Wuhan, China (11), or were designed explicitly as interventions, for example, as in Slovakia (12). Here we show results from the Real-time Assessment of Community Transmission-1 (REACT-1) study, a representative community-wide program that is tracking prevalence of SARS-CoV-2 across England through repeated random population-based sampling (13). This program was designed to rapidly detect resurgence of SARS-CoV-2 transmission, including at low prevalence, thus providing early warning of any upturn in infections, which can help with policy response and enable timely implementation of public health interventions.
Over the course of four rounds, from 1 May to 8 September 2020, we invited more than 2.4 million people to join the study, from whom we obtained ~596,000 tested swabs (Table 1) for an overall response rate of ~25% (table S1). Between round 1 (1 May to 1 June 2020) and round 2 (19 June to 7 July) there was a fall in weighted prevalence from 0.16% (95% confidence interval: 0.12%, 0.19%) to 0.088% (0.068%, 0.11%) (Table 1 and Fig. 1). Infections fell further, to their lowest observed value, in round 3 (24 July to 11 August), with 54 positive samples out of 161,560 swabs, giving a weighted prevalence of 0.040% (0.027%, 0.053%). In comparison, a 100-fold higher prevalence of ~5% was seen at the peak of the first UK wave, based on a daily incidence of infection in the UK of >300,000 (14) and assuming that individuals would test swab-positive for ~10 days on average (15). Prevalence then increased in round 4 (20 August to 8 September), where we found 137 positive samples out of 154,325 swabs, giving a weighted prevalence of 0.13% (0.10%, 0.15%).
(A) Model fits to REACT-1 data for sequential rounds 1 and 2 (yellow), 2 and 3 (blue), and 3 and 4 (green). Vertical lines show 95% prediction intervals for models. Black points show observations. See Table 1 for R estimates. (B) Models fit to individual rounds only (red). Note that only 585,004 of 596,965 tests had dates available and were included in the analysis (465 out of 473 positives were included).
” data-icon-position=”” data-hide-link-title=”0″>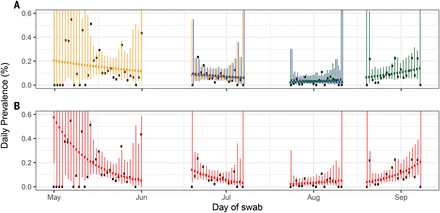
(A) Model fits to REACT-1 data for sequential rounds 1 and 2 (yellow), 2 and 3 (blue), and 3 and 4 (green). Vertical lines show 95% prediction intervals for models. Black points show observations. See Table 1 for R estimates. (B) Models fit to individual rounds only (red). Note that only 585,004 of 596,965 tests had dates available and were included in the analysis (465 out of 473 positives were included).
Using a model of constant exponential growth and decay (16), we quantified this fall and rise in prevalence in terms of halving and doubling times and reproduction number R (Fig. 1 and Table 2). Over rounds 2 and 3 (19 June to 11 August), prevalence fell with an estimated halving time of 27 days (95% credible intervals: 20, 42) corresponding to an R value of 0.85 (0.79, 0.90). Prevalence then increased over rounds 3 and 4 (24 July to 8 September), with a doubling time of 17 (14, 23) days corresponding to an R value of 1.28 (1.20, 1.36). Our estimates of R and doubling times were similar in sensitivity analyses among nonsymptomatic people [average 72% (95% confidence interval: 67%, 76%)] or those positive for both the envelope protein (E) gene and nucleocapsid protein (N) gene (table S2).
We compared epidemic trends estimated from the REACT-1 data above with those based on routine surveillance data (Fig. 1, figs. S1 and S2, and Table 2) over the same period. Numbers of routine surveillance cases were growing from the start of round 2 to the end of round 3 (19 June to 11 August), with a corresponding R of 1.05 (1.02, 1.07) (Table 2), when swab positivity was declining in REACT-1. R estimates from routine surveillance data were likely upwardly biased, because there was a near-doubling of test capacity during this period (17) (fig. S1). These findings are consistent with experience in the UK during the 2009 influenza pandemic, when there were substantial temporal variations in the sensitivity of case-based polymerase chain reaction surveillance (18).
We also observed an apparent shift from decline to growth using within-round data (fig. S3 and Table 2). During round 3 (24 July to 11 August), with 94% probability, the epidemic had started to grow with a doubling time of 14 days (95% credible interval: from halving every 59 days to doubling every 6.4 days), corresponding to an R of 1.34 (0.93, 1.83) (Fig. 1 and Table 1). During round 4 (20 August to 8 September), the doubling time decreased to 8.0 (5.7, 14) days, with an R of 1.64 (1.35, 1.95). In response to the rapidly increasing epidemic, the UK government announced a more stringent social distancing measure called the “rule of six,” prohibiting gatherings of more than six people (19).
We relaxed our assumption of constant growth or decay using a flexible p-spline (16) (fig. S1) and inferred a plateau or slight increase in prevalence in July 2020 in the gap between rounds 2 and 3. As a result, the prevalence for round 3 started higher than expected from the data observed at the end of round 2, a pattern similar to that seen in data from the Office for National Statistics Coronavirus (COVID-19) Infection Survey pilot (20). Using the p-spline, we estimated that lowest prevalence occurred on 20 July (13 July, 15 August) (fig. S3), compared with 5 July (30 June, 16 July), as estimated from the routine surveillance data, likely reflecting the rapid increase in testing capacity (fig. S3).
During March and April, the highest prevalence regionally was recorded in London, which experienced the highest incidence of cases during the first wave (21, 22). Prevalence fell in all regions between round 1 (1 May to 1 June) and round 3 (24 July to 11 August). There was then positive growth (>95% probability) between round 3 and round 4 (20 August to 8 September) in all regions except East and West Midlands (table S3 and figs. S4 and S5), with the highest growth in the North East region [R = 1.67 (1.20, 2.48)]. During round 4 (20 August to 8 September), we observed about a threefold difference between the highest prevalence in both the North West region at 0.17% (0.12%, 0.24%) and Yorkshire and the Humber at 0.17% (0.11%, 0.27%) and the lowest at 0.06% (0.04%, 0.09%) in the South East region (Fig. 2, table S4, and fig. S4).
Covering four rounds of the REACT-1 study by (A) age, (B) employment type, (C) ethnicity, and (D) region. Vertical bars show 95% confidence intervals. Rounds are differentiated by color.
” data-icon-position=”” data-hide-link-title=”0″>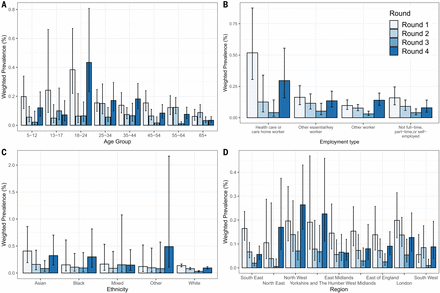
Covering four rounds of the REACT-1 study by (A) age, (B) employment type, (C) ethnicity, and (D) region. Vertical bars show 95% confidence intervals. Rounds are differentiated by color.
We found spatial heterogeneity in prevalence at a subregional level using a geospatial model (16) with a range parameter estimate of 22.6 km (95% confidence interval: 16.1, 31.7) (Fig. 3 and table S5). We observed areas of higher prevalence in parts of the North West region, Yorkshire and the Humber, Midlands, and the London conurbation in round 1 (1 May to 1 June). These patterns persisted at lower prevalence in round 2 (19 June to 7 July) before reaching lowest prevalence in round 3 (24 July to 11 August). The epidemic then resurged in round 4 (20 August to 8 September), with geographical patterns similar to those seen in rounds 1 and 2 and an indication that prevalence in each local area had increased between rounds 3 and 4 (fig. S5).
Estimated prevalence from geospatial model for (A) round 1, (B) round 2, (C) round 3, and (D) round 4. Regions: NE, North East; NW, North West; YH, Yorkshire and the Humber; EM, East Midlands; WM, West Midlands; EE, East of England; L, London; SE, South East; SW, South West.
” data-icon-position=”” data-hide-link-title=”0″>