Human know-how derives in part from our nose for novelty — we’re curious creatures, whether looking around corners or testing scientific hypotheses. For artificial intelligence to have a broad and nuanced understanding of the world — so it can navigate everyday obstacles, interact with strangers or invent new medicines — it also needs to explore new ideas and experiences on its own. But with infinite possibilities for what to do next, how can AI decide which directions are the most novel and useful?
One idea is to automatically leverage human intuition to decide what’s interesting through large language models trained on mass quantities of human text — the kind of software powering chatbots. Two new papers take this approach, suggesting a path toward smarter self-driving cars, for example, or automated scientific discovery.
“Both works are significant advancements towards creating open-ended learning systems,” says Tim Rocktäschel, a computer scientist at Google DeepMind and University College London who was not involved in the work. The LLMs offer a way to prioritize which possibilities to pursue. “What used to be a prohibitively large search space suddenly becomes manageable,” Rocktäschel says. Though some experts worry open-ended AI — AI with relatively unconstrained exploratory powers — could go off the rails.
How LLMs can guide AI agents
Both new papers, posted online in May at arXiv.org and not yet peer-reviewed, come from the lab of computer scientist Jeff Clune at the University of British Columbia in Vancouver and build directly on previous projects of his. In 2018, he and collaborators created a system called Go-Explore (reported in Nature in 2021) that learns to, say, play video games requiring exploration. Go-Explore incorporates a game-playing agent that improves through a trial-and-error process called reinforcement learning (SN: 3/25/24). The system periodically saves the agent’s progress in an archive, then later picks interesting, saved states and progresses from there. But selecting interesting states relies on hand-coded rules, such as choosing locations that haven’t been visited much. It’s an improvement over random selection but is also rigid.
Clune’s lab has now created Intelligent Go-Explore, which uses a large language model, in this case GPT-4, instead of the hand-coded rules to select “promising” states from the archive. The language model also picks actions from those states that will help the system explore “intelligently,” and decides if resulting states are “interestingly new” enough to be archived.
LLMs can act as a kind of “intelligence glue” that can play various roles in an AI system because of their general capabilities, says Julian Togelius, a computer scientist at New York University who was not involved in the work. “You can just pour it into the hole of, like, you need a novelty detector, and it works. It’s kind of crazy.”
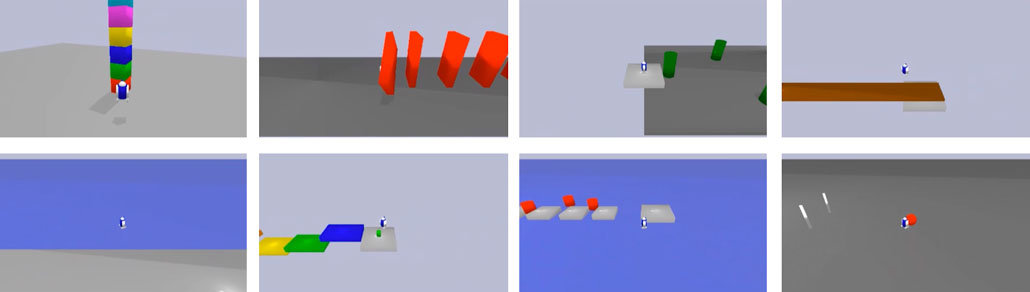
The researchers tested Intelligent Go-Explore, or IGE, on three types of tasks that require multistep solutions and involve processing and outputting text. In one, the system must arrange numbers and arithmetic operations to produce the number 24. In another, it completes tasks in a 2-D grid world, such as moving objects, based on text descriptions and instructions. In a third, it plays solo games that involve cooking, treasure hunting or collecting coins in a maze, also based on text. After each action, the system receives a new observation — “You arrive in a pantry…. You see a shelf. The shelf is wooden. On the shelf you can see flour…” is an example from the cooking game — and picks a new action.
The researchers compared IGE against four other methods. One method sampled actions randomly, and the others fed the current game state and history into an LLM and asked for an action. They did not use an archive of interesting game states. IGE outperformed all comparison methods; when collecting coins, it won 22 out of 25 games, while none of the others won any. Presumably the system did so well by iteratively and selectively building on interesting states and actions, thus echoing the process of creativity in humans.
IGE could help discover new drugs or materials, the researchers say, especially if it incorporated images or other data. Study coauthor Cong Lu of the University of British Columbia says that finding interesting directions for exploration is in many ways “the central problem” of reinforcement learning. Clune says these systems “let AI see further by standing on the shoulders of giant human datasets.”
AI invents new tasks
The second new system doesn’t just explore ways to solve assigned tasks. Like children inventing a game, it generates new tasks to increase AI agents’ abilities. This system builds on another created by Clune’s lab last year called OMNI (for Open-endedness via Models of human Notions of Interestingness). Within a given virtual environment, such as a 2-D version of Minecraft, an LLM suggested new tasks for an AI agent to try based on previous tasks it had aced or flubbed, thus building a curriculum automatically. But OMNI was confined to manually created virtual environments.
So the researchers created OMNI-EPIC (OMNI with Environments Programmed In Code). For their experiments, they used a physics simulator — a relatively blank-slate virtual environment — and seeded the archive with a few example tasks like kicking a ball through posts, crossing a bridge and climbing a flight of stairs. Each task is represented by a natural-language description along with computer code for the task.
OMNI-EPIC picks one task and uses LLMs to create a description and code for a new variation, then another LLM to decide if the new task is “interesting” (novel, creative, fun, useful and not too easy or too hard). If it’s interesting, the AI agent trains on the task through reinforcement learning, and the task is saved into the archive, along with the newly trained agent and whether it was successful. The process repeats, creating a branching tree of new and more complex tasks along with AI agents that can complete them. Rocktäschel says that OMNI-EPIC “addresses an Achilles’ heel of open-endedness research, that is, how to automatically find tasks that are both learnable and novel.”
It’s hard to objectively measure the success of an algorithm like OMNI-EPIC, but the diversity of new tasks and agent skills generated surprised Jenny Zhang, a coauthor of the OMNI-EPIC paper, also of the University of British Columbia. “That was really exciting,” Zhang says. “Every morning, I’d wake up to check my experiments to see what was being done.”
Clune was also surprised. “Look at the explosion of creativity from so few seeds,” he says. “It invents soccer with two goals and a green field, having to shoot at a series of moving targets like dynamic croquet, search-and-rescue in a multiroom building, dodgeball, clearing a construction site, and, my favorite, picking up the dishes off of the tables in a crowded restaurant! How cool is that?” OMNI-EPIC invented more than 200 tasks before the team stopped the experiment due to computational costs.
OMNI-EPIC needn’t be confined to physical tasks, the researchers point out. Theoretically, it could assign itself tasks in mathematics or literature. (Zhang recently created a tutoring system called CodeButter that, she says, “employs OMNI-EPIC to deliver endless, adaptive coding challenges, guiding users through their learning journey with AI.”) The system could also write code for simulators that create new kinds of worlds, leading to AI agents with all kinds of capabilities that might transfer to the real world.
Should we even build open-ended AI?
“Thinking about the intersection between LLMs and RL is very exciting,” says Jakob Foerster, a computer scientist at the University of Oxford. He likes the papers but notes that the systems are not truly open-ended, because they use LLMs that have been trained on human data and are now static, both of which limit their inventiveness. Togelius says LLMs, which kind of average everything on the internet, are “super normie,” but adds, “it may be that the tendency of language models towards mediocrity is actually an asset in some of these cases,” producing something “novel but not too novel.”
Some researchers, including Clune and Rocktäschel, see open-endedness as essential for AI that broadly matches or surpasses human intelligence. “Perhaps a really good open-ended algorithm — maybe even OMNI-EPIC — with a growing library of stepping stones that keeps innovating and doing new things forever will depart from its human origins,” Clune says, “and sail into uncharted waters and end up producing wildly interesting and diverse ideas that are not rooted in human ways of thinking.”
Many experts, though, worry about what could go wrong with such superintelligent AI, especially if it’s not aligned with human values. For that reason, “open-endedness is one of the most dangerous areas of machine learning,” Lu says. “It’s like a crack team of machine learning scientists trying to solve a problem, and it isn’t guaranteed to focus on only the safe ideas.”
But Foerster thinks that open-ended learning could actually increase safety, creating “actors of different interests, maintaining a balance of power.” In any case, we’re not at superintelligence yet. We’re still mostly at the level of inventing new video games.